

본 게시물은 학부 '생물정보학(Bioinformatics)' 강의를 토대로 필자가 이해한 내용을 정리하였습니다.
바이오 빅데이터의 생산 과정
Large datasets generated by complex equipment
- Data management - storage, transfer, data transformation : domain of Information Technology
- Data analysis - mapping, assembly, algorithm scaling : domain of Computer Science
- Statistical challenges - traditional statistiscs is not well suited for modeling systematic errors over large number of observations : domain of Statistics
- Biological hypothesis testing - data interpretation : domain of Life Science
바이오 빅데이터를 생산하는 과정은 복잡한 장비를 통해 대규모 데이터를 생성하는 것으로부터 시작된다.
- 데이터 관리 - 저장, 전송, 데이터 변환
- 분야 : 정보 기술(Information Technology)
- 데이터 분석 - 매핑, Assembly, 알고리즘 확장
- 분야 : 컴퓨터 과학(Computer Science)
- 통계적 과제 - 전통적인 통계는 많은 관측치에서 체계적인 오류를 모델링하는 데 적합하지 않다.
- 분야 : 통계학(Statistics)
- 생물학적 가설 검증 - 데이터 해석
- 분야 : 생명과학(Life Science)

Command Line Tools : 쉽게 말하면 Linux를 떠올리면 된다. 오로지 키보드를 통해 적은 명령어로 모든 조작이 가능하다.
이를 편리하게 하기 위해 마이크로소프트, 애플 등에서 여러 운영체제를 만들어 내어 Graphical User Interfaces, 즉 GUI를 만들어 내어 마우스로도 쉽게 조작이 가능하게 되었다. 그리고 그 사이 명령어와 마우스 명령 모두 하이브리드로 가능한 모델이 R Programming Environment이다.
Omics Sciences
기초 오믹스 : Genomics, Transcriptomics, Proteomics, Metabolomics, Phenomics
바이오 빅데이터를 위해 기초 오믹스는 이해하고 가야할 필요가 있다. 학부 과목의 경우, 세포생물학, 생화학, 분자생물학, 유전학은 필수.
그리고 이제는 대통합의 시대. 이제 개인중심 소규모 연구가 아닌 과학 분야들의 융합연구가 주를 이룬다. 트렌드라고 볼 수 있겠다. 우리가 이제 교수가 되거나 어느 정출연의 연구원이 되었다 해도 혼자로는 감당할 수 없는 스케일의 연구 주제들이 되었다. 유전체를 연구하면 유전체학, 전사체를 연구하면 전사체학, 단백체를 연구하면 단백체학. 모든 작아보이는 물질조차도 하나의 학문으로서 연구 주제이자 그 전체를 연구하는 Omics science가 되었다.
생물학의 범위가 DNA에서부터 Metabolite(신진대사)까지. 이를 종합적으로 연구를 하기에는 너무 역부족이다. 그래서 학자들은 각 물질부터 과정의 각각의 분야를 학문으로 나누어 오랫동안 연구를 진행하였다.
Genome -> Transcriptome -> Proteome -> Metabolome 에 이르면서 이에 따라 학문도 따라간다.
Genomics -> Transcriptomics -> Proteomics -> Metabolomics
우리는 이를 통틀어 Omics Sciences라고 한다.
유전자를 이해하기 위한 Genomics
그 유전자를 발현하기 위해 전사 과정을 이해하기 위한 Transcriptomics
전사 이후 번역되는 단백질의 과정을 이해하기 위한 Proteomics
그러한 일련의 과정들 즉, 대사를 이해하기 위한 Metabolomics
더 나아가 세포 수준까지에 이르러 발현된 형질을 이해하기 위한 Phenomics 에 이르는 시대가 되었다. 이제 트랜드는 Phenomics. Cellular component는 세포 내를 이야기하는 것.
Macro molecule : 핵산, 단백질, 지질, 탄수화물
이 Macromolecule이 assemble 되어서 DNA, Protein, Lipid, Polysacharride가 되고 이들은 모두 monomer가 존재한다.
단지 저장할때 polymer 형태가 효율적이기 때문에 polymer 형태가 존재하는 것.
우리 몸은 monomer가 필요하다. 그래야 이용할 수 있다.
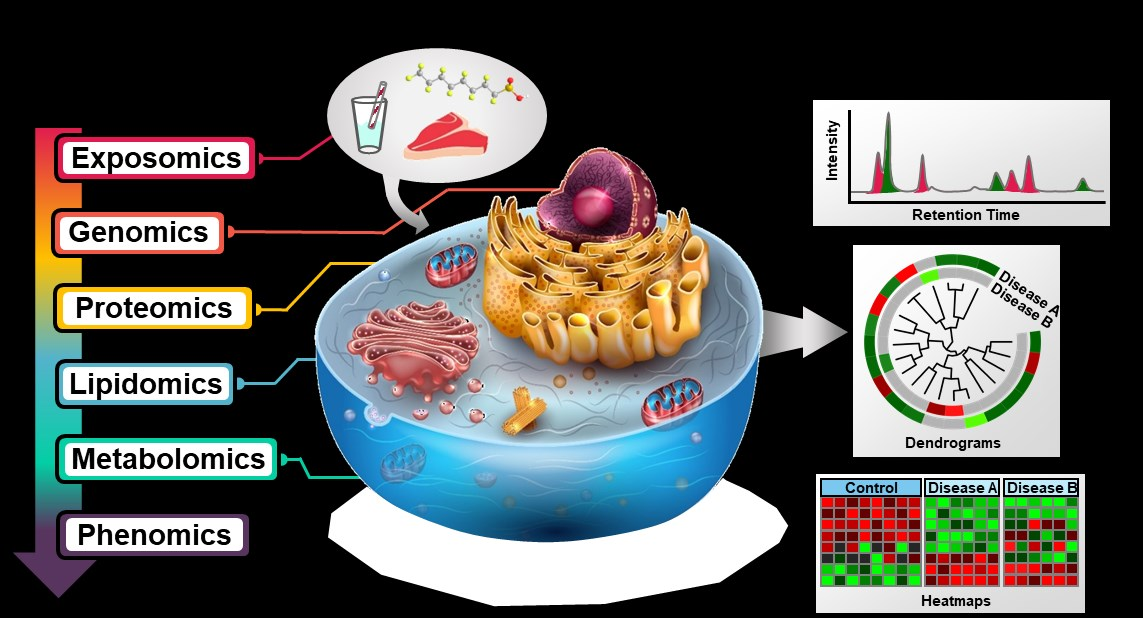
규칙성이 보인다. 결국 우리가 새로운 것을 발견해서 Omics 라는 이름을 붙이면 그건 내가 만든 학문이 된다는 것. 이 모든걸 다 묶어서 Multi Omics라고 한다. 즉, 모두 기초 오믹스를 기반으로 해서 파생된 것들.. 어떻게 보면 이 Exosomics, Endosomics에는 DNA, 단백질, Metabolite 등등이 섞여있을 것이고 Lipidomics의 경우도 metabolite에서 파생된 것이라 볼 수 있다. 기초 오믹스로부터 다른 오믹스들이 계속해서 파생되어 가고 있는 것.
우리는 이제 Data interpretation(해석), Data analysis(분석)을 명확히 구분해야한다. 보통 사람들을 이를 하나로 보는 경향이 있다. 하지만 생물정보학에서 하나로 보면 안된다. 분석은 파이프라인 하나만 있으면 된다. 프로그램을 짰다면 배포를 하고 그때부터 엔터만 누르면 분석은 누구나 쉽게 할 수 있다. 즉, 돈만 있으면 분석은 누구나 할 수 있다.
하지만, Interpretation(해석)은 아무나 할 수 없다. 즉, 생물정보학을 배운 우리가 아니면 다른 사람은 할 수 없다는 것. Data에서 나오는 의미를 찾아서 그 의미가 나에게 어떤 혜택을 주는가에 의해 특허를 낼 수도 있고, 학위를 받을 수도 있는 것이다.

Computational bioinformatics : 말 그대로 프로그래밍. 생물학도의 field는 아니다. 컴퓨터 공학자들이 프로그래밍을 하고 소프트웨어 분야 종사자의 분야라 봐야할 것. 내 자신이 코딩을 할 수 있다면 연구를 하면서 어떠한 tool이 필요하게 될 때 만들어볼 수도 있을 것이다.
Structural bioinformatics : alphafold가 그 예.
현재 systems biology : Structural Bioinformatics, Comparative Bioinformatics, Functional genomics
왜 우리는 Multi Omics에 주목해야 하는가?
결국 Data integration 때문이다.
단백질만을 연구한다고 해서 단백질에 대한 것만 연구할 수는 없다. 단백질에 대한 RNA 또는 DNA적으로, 효소로서 작용하면 그것들은 Metabolite에 대한 data로 다 연결되어 있을 것이다.
그래서 우리는 이 데이터를 본격적으로 수집하기 위해 게놈 프로젝트를 시작했다.
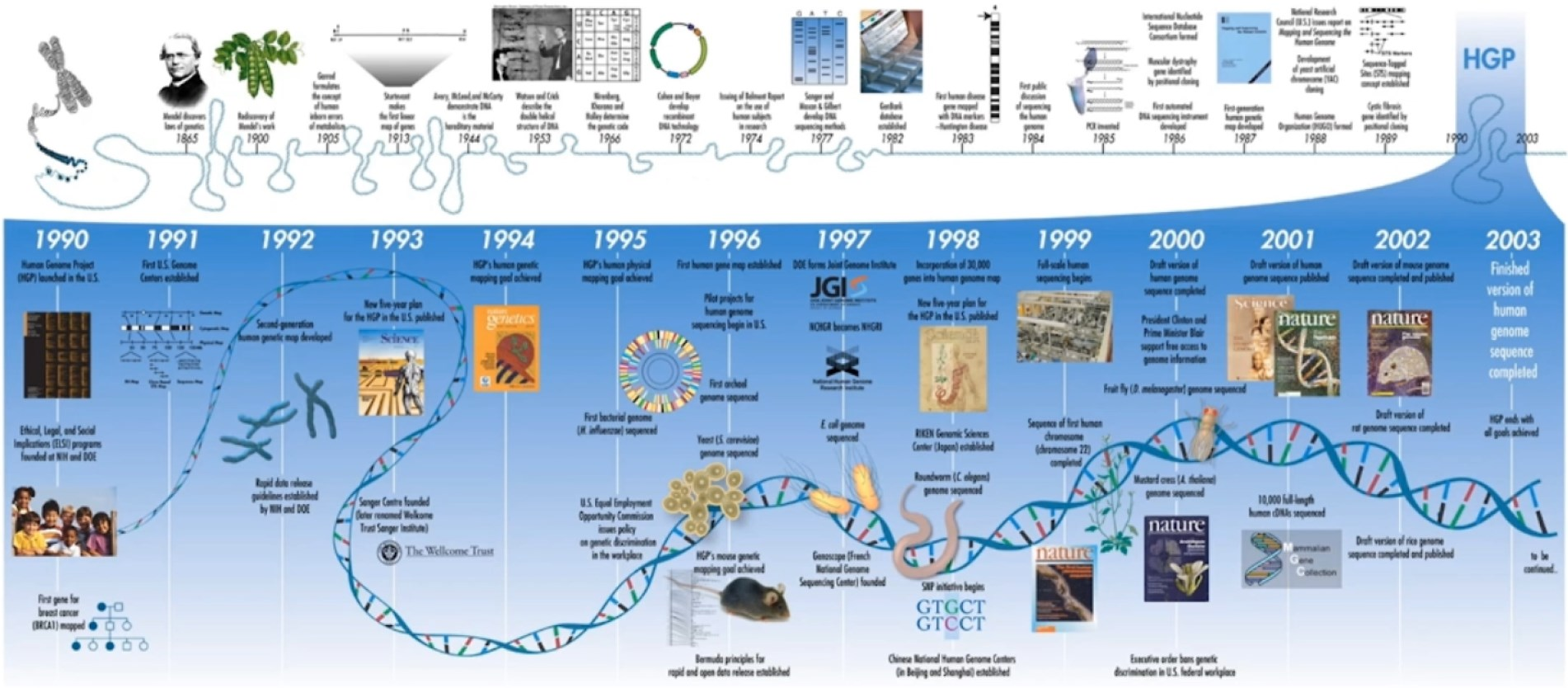
동물원에서 볼 수 있는 유명한 동물들은 현재 웬만하면 모두 게놈프로젝트가 끝났다고 보면 된다. 그리고 지금도 게놈프로젝트는 활발히 진행중이다.
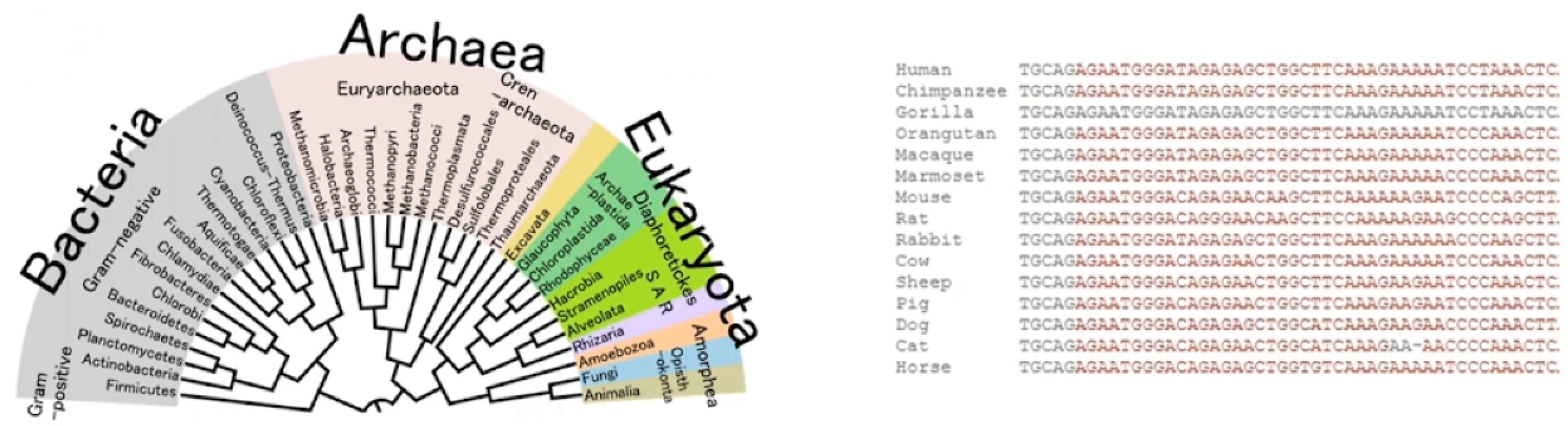
Bacteria, Archaea, Eukaryota 3분류로 omics data들을 나눈다면 진화적인 관점을 비교할 때 서열의 비교를 얼라이먼트라고 한다. 즉, 정렬.
다시 말해, DNA, RNA 또는 아미노산 서열을 정렬하는 것. 생물학계에서 자주쓰는 BLAST에서 A가 alignment이다.
인간부터 말까지... 모두 다른 종이다. 다 다른 종인데 특정 하나의 유전자 차이가 이러한 나비효과를 불러왔다. 하나의 유전자를 alignment를 했는데 누구는 비슷하고 누구는 안비슷했던 것. 이것들을 진화적으로 유전 다양성이 가깝냐 여부를 판단할 수 있게된다. 진화적으로 가까우면 alignment가 잘되는 것, 멀면 alignment가 안된다고 본다.
SNP도 마찬가지. 예를 들어 한 염기가 A, T, G, C 중에 다른 염기로 바뀌었다면 그것이 SNP. 이 SNP를 찾을 때에도 alignment를 해야만 찾을 수 있다.
그래서 생물정보학에서 alignment 개념은 상당히 중요하다.
피노타입 결과를 표현하는 방법
Dendrogram, Heatmap

인간과 침팬지는 유전자가 98% 비슷하다. DNA는 30억개인데 2%라 해도 엄청나게 많은 숫자이다.
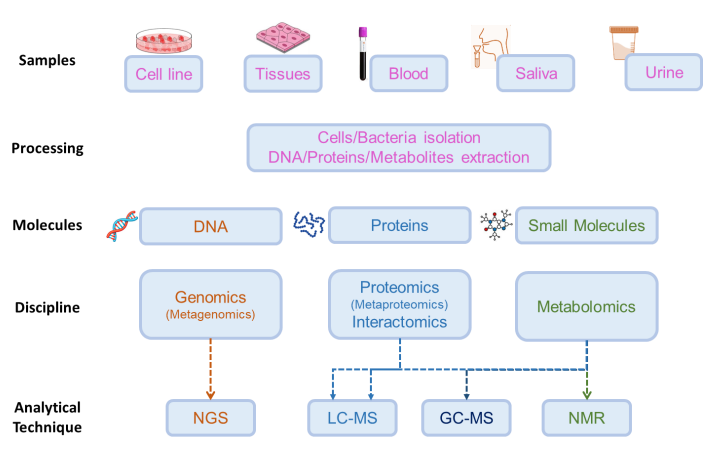
Specific Gene : 특이반응 유전자.
우리가 검사하는 유전자를 찾으려면 그 검사하고자 하는 병, 예컨대 탈모에 관한 또는 피부병에 관한, 아니면 암에 관련된 것 등. 암도 종류가 많기에, 이들을 모두 분류하고 진다하려면 그 많은 종류들의 특이한 점을 각각 찾아야 마커가 된다. 남들 다 나오는 것들은 마커가 되면 안될 것이다.
특이반응 유전자를 찾는 가장 쉬운 방법이 전사체를 분석하는 것. 물론 실험으로 검증을 해야하지만 Central Dogma 덕에 우리는 손쉽게 찾을 수 있었다. 과거에도.
'BIOLOGY > Bioinformatics' 카테고리의 다른 글
| 데이터 만들기 a.k.a 데이터 생산 (3) | 2024.10.19 |
|---|---|
| Sequencing에 점수를, Phred score (0) | 2024.10.18 |
| 저는 NGS를 하고 싶어요. (0) | 2024.10.18 |
| 생명과학의 미래, NGS(차세대 염기서열 분석) (2) | 2024.10.15 |
| 생물학, 그리고 코딩을 곁들인 (1) | 2024.09.06 |
나의 성장 드라마
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!



