

본 게시글은 학부 '생물정보학(Bioinformatics)' 강의를 토대로 필자가 이해한 내용을 정리하였습니다.
데이터가 어떻게 생겨나는지 알아보았다. 언급했던 회사에 취직하지 않는 이상 우리가 직접 만들어내는 일은 없지 않을까. 그래서 한낱 머글에 불과한 우리는 연구진들이 만들어 놓은 데이터를 다운받아서 사용할 것이다.
데이터가 의미를 가지고 공신력이 생기려면 어디에 보관되어있는지 기록되어 있고, 누구나 다운로드 받을 수 있어야 한다. Data가 Deposit되어 있어야 한다는 것.
이제 데이터를 쇼핑하러 가자.

미국 : NCBI
유럽 : EBI
일본 : DDBJ
중국 : CNBGNG
한국 : KBDS
중국은 현재 NCBI와 정보를 공유하고 있지 않다. NCBI와 같은 사이트는 일종의 클라우드 개념이라 이해하면 된다.
NCBI SRA 접속
SRA : Sequence Read Archive
수많은 데이터 안에서 우리가 원하는 데이터를 찾으려면 검색도 잘해야 한다. 그래서 넓은 범위에서 점점 좁은 범위의 키워드를 적어나가는 것이 효율적이다.
- 관심있는 종(ex. E.coli, COVID19, C.elegans etc.)
- Sequencing 기술명 키워드를 뒤에 추가(ex. RNA seq, DNA seq, Chip seq, DIP seq etc.)
- 내가 연구하고자 하는 분야 키워드 추가
작성 예시 : C.elegans RNAseq developmental stage
검색 결과 화면에서 우측을 보면 위처럼 표가 있다. 그 중 Bioproject에서 public은 누구나 열람이 가능하지만 controlled는 아무나 열람할 수 없다. 185개가 검색이 되었지만 public은 5개 뿐이다. 즉 하나의 여러 개의 샘플이 있다는 것.
Sample이 4갠데 Experiment가 12개라면 3번 반복한 것이다.
필자는 우리를 고생시켰던 코로나 바이러스 중 SARS 바이러스에 대해 찾아보겠다.
그리고 RUNS 항목에 링크되어 있는 SRR12288277을 클릭한다.
다운로드를 하기 위해 FASTA/FASTQ download 항목을 누르자.
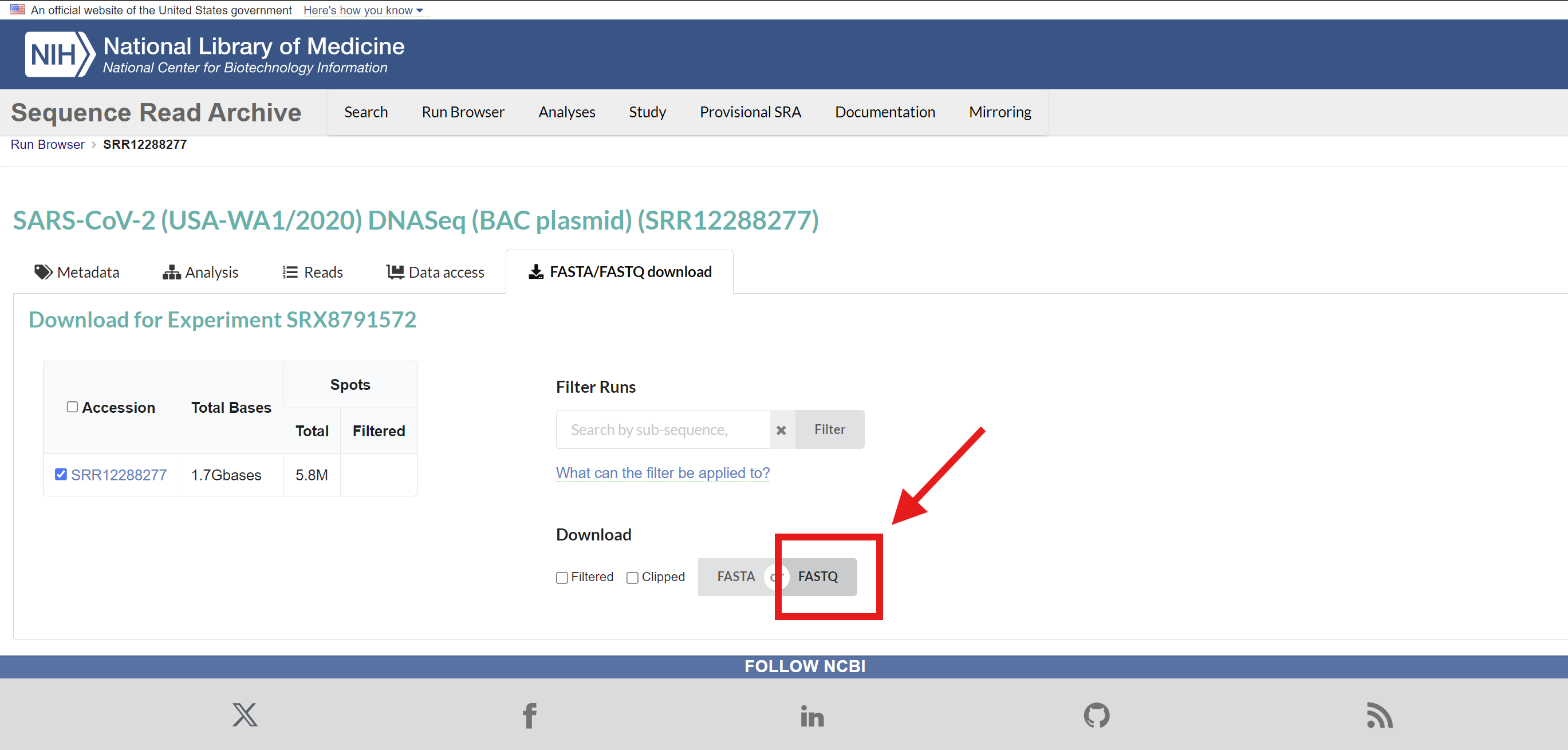
나는 FASTQ를 다운로드 받으려고 한다.
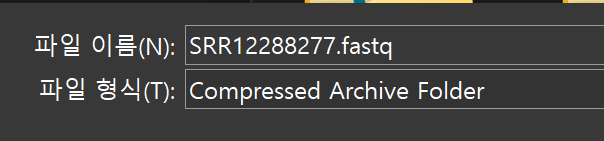
그럼 이 그림처럼 fastq 확장자를 가진 파일이 다운로드 되어 이를 메모장에 읽을 수 있다.
메모장에 열린 4줄의 리드들의 의미는 앞서 게시되어 있는 게시글을 확인하자.
'BIOLOGY > Bioinformatics' 카테고리의 다른 글
| [팀프로젝트] 팀 프로젝트의 서막 (0) | 2024.12.01 |
|---|---|
| 데이터 수집부터 Alignment까지 (0) | 2024.10.22 |
| 데이터 만들기 a.k.a 데이터 생산 (3) | 2024.10.19 |
| Sequencing에 점수를, Phred score (0) | 2024.10.18 |
| 저는 NGS를 하고 싶어요. (0) | 2024.10.18 |
나의 성장 드라마
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!
![[팀프로젝트] 팀 프로젝트의 서막](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FW6Sks%2FbtsLaA3lpDG%2FX8MdXzMKVhpKjhOvZp4SX0%2Fimg.png)

