


본 게시물은 대학교 학부 수업 및 참고 교재인 '이제 시작이야! 컴퓨팅 사고력으로 인공지능까지 파이썬 - 전수진, 박주연, 김수환 공저 / 연두에디션' 을 토대로 필자가 이해한 내용을 정리했습니다.

디지몬 덕분에 한 때 우리들의 꿈은 선택받은 아이들이었던 시절이 있었다. 디지몬 어드벤처를 보면서 나도 태일이와 모험하는 듯한 그 설렘은 글을 쓰고 있는 지금의 나에게 아련함을 가져다 주고 있었다. 그리고 우리는 모두 각자의 삶을 선택받아 각자의 모험을 떠나고 있다. 이제 IT의 세상을 살아보려 하는 나는 여기서도 궁금증이 생긴다. 과연 디지몬의 세계처럼 디지털로만 이루어진 세상을 만드는게 가능할 날이 올까?
우리는 유기체로 이루어진 어찌보면 아날로그의 세상이다. 디지털의 기기와 가상현실을 구현해 내고 있지만 우리 그 자체를 디지털화 시키는 건 아직 보여진 바가 없다. 우리를 잘게 쪼개어 데이터화 시킨다면 텔레포트가 가능할 것이라는 낭설을 본 기억이 있다. 비록 이러한 가설들이 근거없는 소문일지라도 그만큼 데이터는 무한한 상상에 가능성을 열어주는 창구일지도 모른다는 생각이 들었다.
이제 데이터의 시대가 도래했다. 한때 정보화 시대라는 문구로 매체에서 강조하던 시절을 지나 이제는 정보, 데이터는 삶에 있어서 매우 필수적인 요소로 자리 잡아가고 있다. 그래서 그많은 데이터 속에서 우리는 살아남아야 한다. 거짓과 진실, 내가 원하는 것과 아닌 것들을 구별하기 위해서는 그만큼 데이터를 함축하고 이를 빠르게 선별할 수 있는 기량이 필요해졌다.
그래서 우리는 그 데이터의 표현과 그 데이터를 함축하는 압축을 알아보려한다.
데이터의 양이 많아졌다는 건 그만큼의 종류도 다양해졌다는 것을 의미할 것이다.
하지만 우리가 사진, 동영상 등으로 다양하게 접하는 정보는 어떠한 형태와 상관없이 컴퓨터에게는 그냥 0, 1로 이루어진 이진법으로만 보일 뿐이다.
아스키 코드 ASCII code

이 0, 1로만 이루어진 컴퓨터 언어를 우리의 문자로 표현하기 위해서는 그 중간 다리 역할을 해줄 코드가 필요했다. 그래서 도입된게 아스키코드.
컴퓨터에서 알파벳 문자를 표현하기 위해 한 글자에 대해 8비트를 할당하여 영어 대문자, 소문자, 숫자, 기호 등을 8비트 숫자들과 매칭해서 나타낸 코드



유니코드 Unicode
ASCII code로는 다 표현하는 데에는 한계가 있다. 세계의 다양한 언어(한국어, 한자어 등)를 표현하기 위해 한 글자를 16비트(2 byte)로 표현한다.


우리가 차는 손목시계만 보아도 아날로그와 디지털의 차이를 분명하게 알 수 있다. 오래된 빈티지 시계 또는 가격대가 나가는 오토매틱 시계 등을 보면 단순히 시침, 분침 그리고 초침만 움직이는 데에도 상당히 많은 기계적인 부품이 들어간다. 하지만 이와 달리 디지털 시계를 보면 배터리 하나로 작동되면서 시간을 보는 방법 또한 상당히 직관적이다. 그리고 달력부터 더 많은 기능들이 들어가 있다. 이것들이 가능한 이유는 디지털이 아날로그에 비해 더 간소화 시킬 수 있는 요소가 많아 그만큼 더 많은 기능을 넣을 수 있게 된 것이라 볼 수 있다.
정보를 디지털로 변환했을 때의 장점
- 저장 공간을 줄일 수 있다.
- 모든 숫자로 표현하기 때문에 암호화할 수 있다. 즉, 안전하다.
- 다양한 프로그램을 사용하면 자료의 수정과 편집을 쉽게 할 수 있다.
- 다른 사람과 빠르게 공유할 수 있다.
- 오랜 시간이 지나도 정보의 품질이 변하지 않도록 할 수 있다.
- 데이터 내의 패턴을 찾아 보다 작은 크기로 압축할 수 있다.
데이터 압축의 목적
여기서 데이터 압축은 데이터를 더 적은 비트로 인코딩 하는 과정을 말한다.
데이터 압축을 통하여 데이터의 저장공간을 확보하고 네트워크를 통해 데이터를 전송할 때의 시간을 단축한다.
데이터 압축의 방식
- 손실압축 : 음악 파일에서 사람이 잘 못 듣는 부분을 잘라내어 압축하고 복원하거나, 이미지 파일에서 원본과 비슷해 보이도록 사람이 인식 가능한 수준에서 색을 제거하여 데이터를 압축하는 등의 방식
- 무손실 압축 : 특정한 길이를 가진 반복의 실행을 부호화하거나, 연결하는 방식을 통해 원본 데이터를 복구할 수 있도록 한 압축 방식
런길이 엔코딩(Run-length encoding) 압축

같은 값이 연속해서 나타날 경우, 반복되는 횟수와 그 해당 값을 이용하여 정보량을 줄이는 방법이다. 이 방법은 실행 길이의 부호화가 3번 이상 반복되는 문자가 있어야 효율적이다. 텍스트의 데이터에서는 사용하는 경우가 적다. 아이콘, 클립아트, 애니메이션 같이 배경의 변화가 없고 연속된 값이 많은 그래픽 이미지에서 사용하기 좋다.

LZ 압축(Lempel-Ziv 코딩)

동일한 어구가 반복적으로 나타나는 경우에 반복된 어구를 별도로 등록한 후, 그 반복되는 어구를 사전에 등록한 위치로 연결해서 출력하는 방법이다.
허프만 압축(Huffman encoding)


빈도수가 많은 글자에는 짧은 비트를 할당하고 빈도수가 적은 경우에는 긴 비트를 할당함으로써 전체의 비트 수를 줄이는 방법이다.
픽셀

각 픽셀의 색상을 간단하게 0과 1로 표현할 수 있다. 물론 흑백 이미지에 한해서다.

우리는 눈을 통해 사물을 직관적으로 받아들이고 이를 뇌에서 처리한다. 하지만 컴퓨터는 그렇지 않다. 컴퓨터는 이진법의 수로 모든 것을 표현한다. 그리고 그 이진법으로 저장되어 있거나 처리된 데이터를 우리에게 표현을 할 때에는 그들만의 방법으로 공정을 거쳐야 할 것이다.
비트맵과 벡터

벡터 : 선의 길이, 색상, 좌표 값 등수식으로 표현하며, 로고나 캐릭터 등에 주로 사용한다.
비트맵 : 픽셀들이 모여 이미지를 구성하는 형태이다. 확대할 경우 픽셀이 흐려지는 현상인 엘리어싱 효과가 일어난다.

위의 그림은 4가지의 경우(00, 01, 10, 11)를 표현할 때를 보여준다. 숫자에서 유추할 수 있듯이 1비트가 아닌 2비트 이상을 사용하게 된다.


위의 색상표에서 알 수 있듯이 각 색마다 고유의 코드를 가진다. 이의 코드는 포토샵 등의 사진, 편집 업무를 해본 사람이라면 익숙할 것이다. 즉, 프로그래밍에 국한된 코드는 아니라는 것. 많은 부분에서 상용화 되어있는 코드이다.

실행길이 압축 방식으로 압축한다면 첫번째 숫자는 흰색의 개수이고 두번째 숫자는 검은색의 개수이다. 이를 숫자로 표현하여 압축코딩으로 표현된다.

일상의 소리 또한 이렇게 코드화 하여 압축이 가능하다. 기술 참 좋다.
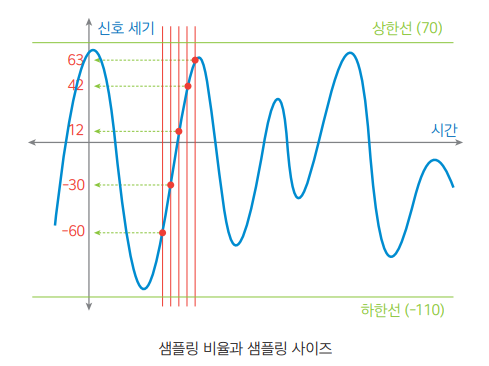
샘플링 비율(Sampling rate)은 잡음에 영향을 준다. 샘플링 사이즈(Sampling size/bit rate)는 음의 섬세함에 영향을 준다.


과학이라는 건 바벨탑이 아닌가 하는 생각이 든다. 인간에게 고등 지식을 준 신이 여기까지 계획을 했던 것일까. 점점 신의 영역에 가까워지는 이 인간의 힘을 볼 때마다 경이롭다. 하지만 그 바벨탑이 무너진 것처럼 이 인간의 금자탑이 무너질 수 있는걸까... 놀라움과 동시에 두려움을 느끼게 되는 오늘.
'CS & AI > Computational thinking' 카테고리의 다른 글
| 스카이넷 vs 자비스 (1) | 2024.07.03 |
|---|---|
| 컴퓨터의 성장 스토리.. 들어보실래요? (5) | 2024.06.17 |
| 조회수, 알고리즘의 은총 (0) | 2024.06.17 |
| 프로그래밍, 너 T발 C야? (0) | 2024.06.16 |
| 뻔하다 뻔해!! 다 보인다고 (1) | 2024.06.16 |
나의 성장 드라마
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!



