![[Coursera] MobileNet | Deep Learning Specialization](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FcgD8bz%2FdJMcaaFDRvz%2FAAAAAAAAAAAAAAAAAAAAAJXoxkrm7EuWKF_FQT5Kxwkrc8GAkuV8_rvoPBZqHS0v%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1782831599%26allow_ip%3D%26allow_referer%3D%26signature%3D4Paft91qMTS3WsZDBb1YLTg2Cso%253D)



ResNet으로 정확도는 충분히 올라갔습니다.
하지만 늘 trade-off는 존재하는 법.
새로운 문제가 발생합니다.
이걸 휴대폰에서 돌리고 싶은데...
ResNet-50을 핸드폰에서 돌리려면 한 장 추론에 몇 초씩 걸려요. 자율주행차의 실시간 인식, 스마트 카메라의 즉각적인 분류 이런 작업들 다 이제 못하게 되죠.

세상에 천재는 많습니다.
Google의 Howard 팀이 답을 가져왔네요.
정확도는 좀 양보하더라도 계산량을 확 줄이자
이게 MobileNet의 마인드에요.
Normal Convolution의 비효율성

먼저 normal convolution이 뭘 하는지 다시 봐볼께요.
3x3x3 filter 하나는 입력의 한 위치에서
3x3 영역의 픽셀을 보고 3개의 channel을 모두 동시에 봅니다. 한 위치당 27번의 곱셈.
공간(spatial) 정보와 channel(depth) 정보를 한꺼번에 처리하는 거죠.
총 계산량을 계산하면
$$(3*3*3)*(4*4)*5 = 2160 multiplications$$
MobileNet의 통찰
공간 처리랑 channel 처리를 분리하면 어떨까?
이게 depthwise seperable convolution의 핵심. 한 번에 다 하지 말고, 두 단계로 나누자는 겁니다.
Step 1. Depthwise Convolution

- Filter는 $f$ x $f$ 크기 - channel 차원 없음
- Filter 개수는 입력 channel과 동일
- 각 filter는 자기 channel 하나에만 적용
빨간 channel에는 빨간 filter, 초록 channel에는 초록 filter, 파란 channel에는 파란 filter.
서로 안섞이고 따로 처리해요. 출력은 4 x 4 x 3로 channel 수는 그대로.
한 위치당 곱셈이 9번. normal은 27번이었죠. 총 계산량은
$$9*16*3 = 432 multiplications$$
Step 2. Pointwise Convolution
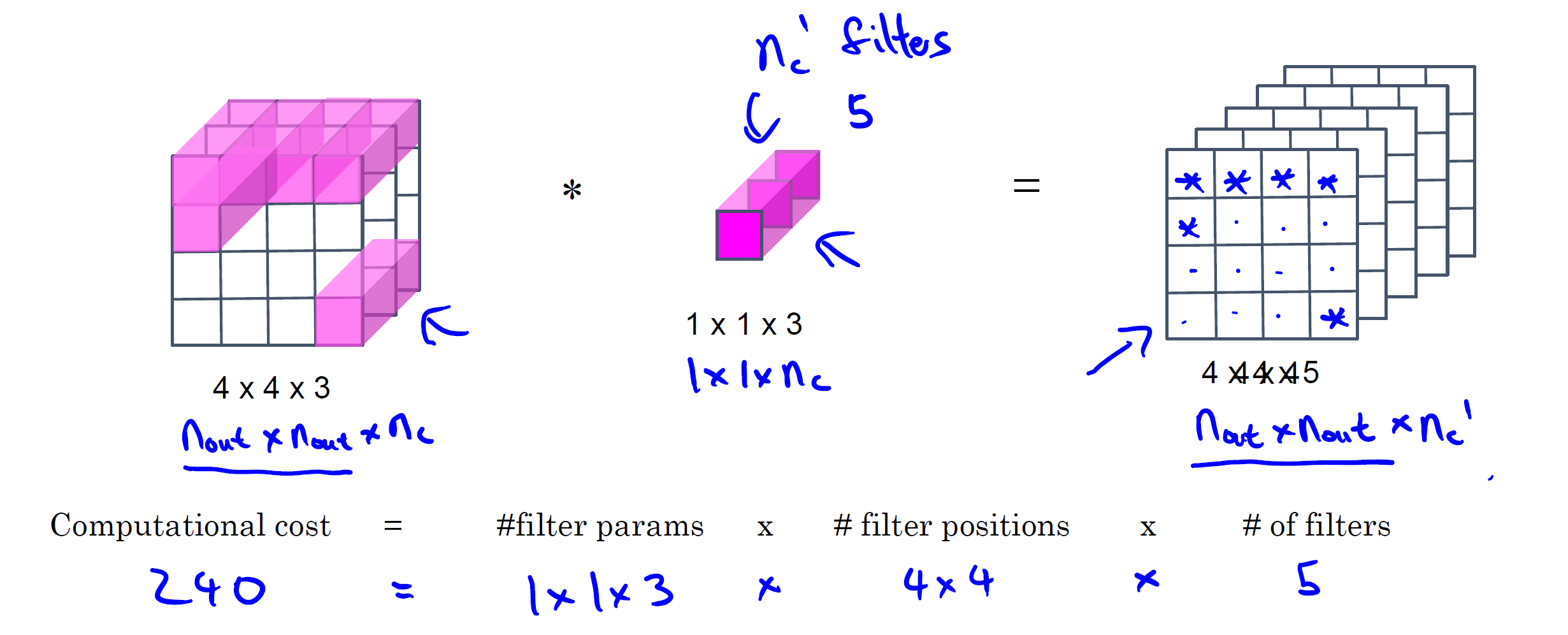
이건 그냥 1x1 convolution이에요.
Filter: 1 x 1 x 3 channel 차원은 입력과 동일
Filter 개수: 출력 channel 수 (e.g. 5개)
출력: 4 x 4 x 5
이 단계의 역할은 두 가지
Channel 간 정보 섞이 - depthwise에서는 못한 것
Channel 수 변환(3 $\rightarrow$ 5)
계산량은
$$3*16*5 = 240 multiplications$$
아래에 두 방식의 dataflow를 같이 보면 훨씬 와닿아요.

약 $\frac{1}{3}$ 수준으로 줄었어요. 그리고 실제 신경망(e.g. 출력 채널 512, fitler 3*3)에서는 약 $\frac{1}{9}$까지 줄어요. 10배 빠른 셈이죠.
우리가 요리를 해본다고 상상해보죠.
- Normal conv: 한 명의 요리사가 재료 손질, 양념, 조리를 한 번에 다 합니다.
- Depthwise: 재료 손질 담당 - 각 재료를 따로 다듬음
- Pointwise: 양념, 조리 담당 - 다듬어진 재료들을 섞고 양념
분업하면 각 단계가 단순해져요. 그리고 최종 겨로가의 품질은 별 차이가 없죠. MobileNet의 효율성은 이 분업에서 옵니다.
MobileNet v1 vs v2

원래 MobileNet v1(2107)은 위에서 설명한 depthwise separable conv를 13번 쌓고 끝나는 단순한 구조였어요.
2019년에 나온 v2는 두 가지를 추가해요.
Residual connection (from ResNet)
Expansion $\rightarrow$ Depthwise $\rightarrow$ Projection 구조 (Inverted Bottleneck)

Inverted Bottleneck이 뭔냐면요.
먼저 아래의 블록의 흐름을 봅시다.
| 단계 | 연산 | 효과 |
| Expansion | 1 x 1 conv | Channel을 확장 - 보통 6배 |
| Depthwise | 3 x 3 depthwise conv | 풍부한 표현 공간에서 공간 처리 |
| Projection | 1 x 1 conv | Channel을 다시 축소 |
블록 내부에서는 풍부한 표현(많은 channel)으로 학습하지만, 블록 외부로 전달할 때는 작은 채널로 압축해서 전달해요.
메모리 효율을 위한 트릭이죠. 모바일 환경에서는 GPU / CPU만큼이나 RAM이 부족하거든요. 블록과 블록 사이의 activation을 작게 유지하면 RAM 사용량이 작아져요.
Depthwise separable convolution으로 nornal conv 대비 약 $\frac{1}{9}$의 계산량을 달성해, 모바일 또는 임베디드 환경에서도 ConvNet을 가능하게 한 모델
CNN의 여러 아키텍쳐의 흐름을 보면 재밌는 점이 있습니다.
각 아키텍쳐가 다음 아키텍쳐의 출발점이 되는 문제를 만들었다는 거에요.
- LeNet을 더 크게 만들면 AlexNet
- AlexNet의 복잡한 hyperparameter를 단순화하면 VGG
- VGG를 더 깊게 쌓으면 ResNet
- ResNet을 휴대폰에서 돌리려면 MobileNet
기술이 발전한다는 게 결국 이런식인가봐요. 하나를 풀면 그게 만든 새로운 문제가 다음 도전이 되고, 그 도전이 새로운 문제르 만들고.

'CS & AI > Computer Vision' 카테고리의 다른 글
| <영상처리> Edge Detection (0) | 2026.06.08 |
|---|---|
| <영상처리> Image Resizing (0) | 2026.06.04 |
| <영상처리> Image Filtering (0) | 2026.06.03 |
| <영상처리> Point Processing (0) | 2026.05.23 |
| [Coursera] ResNet / Deep Learning Specialization (0) | 2026.05.21 |
나의 성장 드라마
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!
