CS & AI/Data Structure
[Java, C++] 리스트(List)
Ungbae
2025. 4. 28. 16:01

본 게시글은 학부 강의 '자료구조', 온라인 강의 'Honglab Data Structure(https://www.honglab.ai/)' 그리고 강의 교재 '자바와 함께하는 자료구조의 이해'의 내용들을 바탕으로 이해한 내용을 정리하였습니다.
단순 연결 리스트(Singly Linked List)

- 동적 메모리 할당을 이용해 리스트를 구현하는 가장 간단한 형태의 자료구조
- 동적 메모리 할당을 받아 노드(Node)를 저장하고, 노드는 레퍼런스를 이용하여 다음 노드를 가리켜 노드를 한 줄로 연결
- Size가 커도 Link를 가져야 하는 단점
- 연결 리스트에서는 삽입이나 삭제 시 다른 노드들의 이동이 불필요
- 배열의 경우 최초에 배열의 크기를 예측하여 결정해야 하므로 대부분의 경우 배열에 빈 공간이 있으나, 연결 리스트는 빈 공간이 없다.
- 연결 리스트에서는 탐색하려면 첫 노드부터 원하는 노드까지 차례로 방문 : 순차 탐색(Sequential Search)
위의 도식화된 그림에서 보았듯이 노드 클래스를 가진다.

Node class
public class Node <E> {
private E item;
private Node<E> next;
public Node(E newItem, Node<E> node){ // 생성자
item = newItem;
next = node;
}
// getter & setter
public E getItem() { return item; }
public Node<E> getNext() { return next; }
public void setItem(E newItem) { item = newItem; }
public void setNext(Node<E> newNext) { next =- newNext; }
}
Slist class
import java.util.NoSuchElementException;
public class SList <E> {
protected Node head; // 연결 리스트의 첫 노드 가리킴
private int size;
public SList(){ // 연결 리스트 생성자
head = null;
size = 0;
}
// 탐색, 삽입, 삭제 연산을 위한 메서드 선언
}
Mehtod
Search()
- target을 찾기 위해 순차 탐색
public int search(E target) { // target을 탐색
Node p = head;
for (int k = 0; k < size; k++) {
if (target == p.getItem()) return k;
p = p.getNext();
}
return -1; // 탐색을 실패한 경우 -1 리턴
}
insertFront()
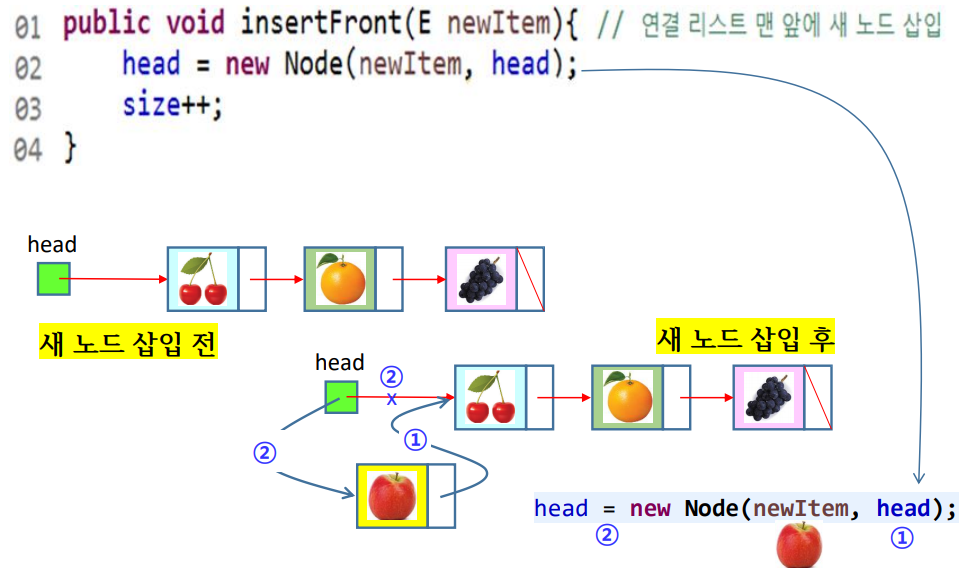
- 새 노드를 맨 앞에 삽입
public void insertFront(E newItem) { // 연결 리스트 맨 앞에 새 노드 삽입
head = new Node(newItem, head);
size++;
}
isertAfter()
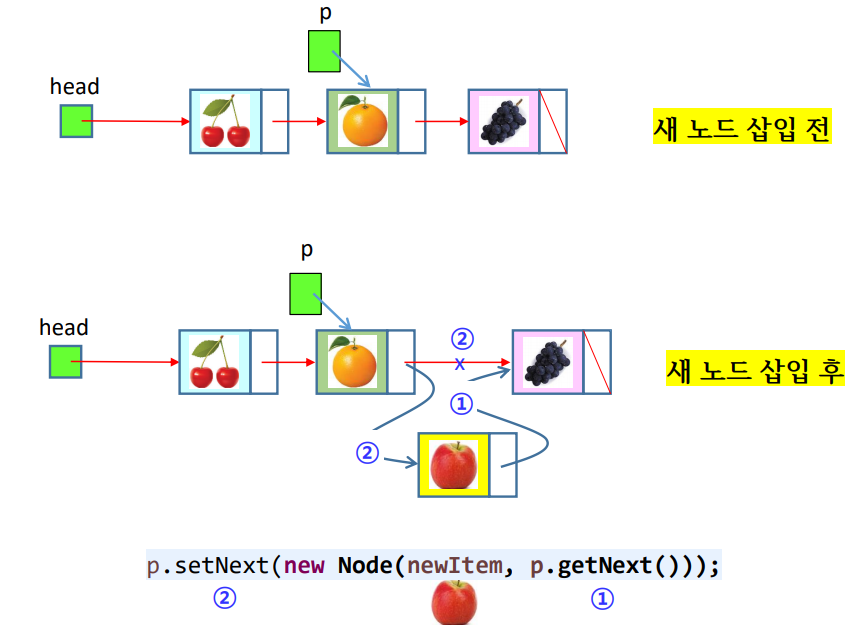
- p 노드의 다음에 새 노드 삽입
public void inserAfter(E newItem, Node p) { // 노드 p 바로 다음에 새 노드 삽입
p.setNext(new Node(newItem, p.getNext()));
size++;
}
deleteFront()

- 첫 노드 삭제
public void deleteFront() { // 리스트의 첫 노드 삭제
if ( size == 0 ) throw new NoSuchElementException();
head = head.getNext();
size--;
}
deleteAfter(p)
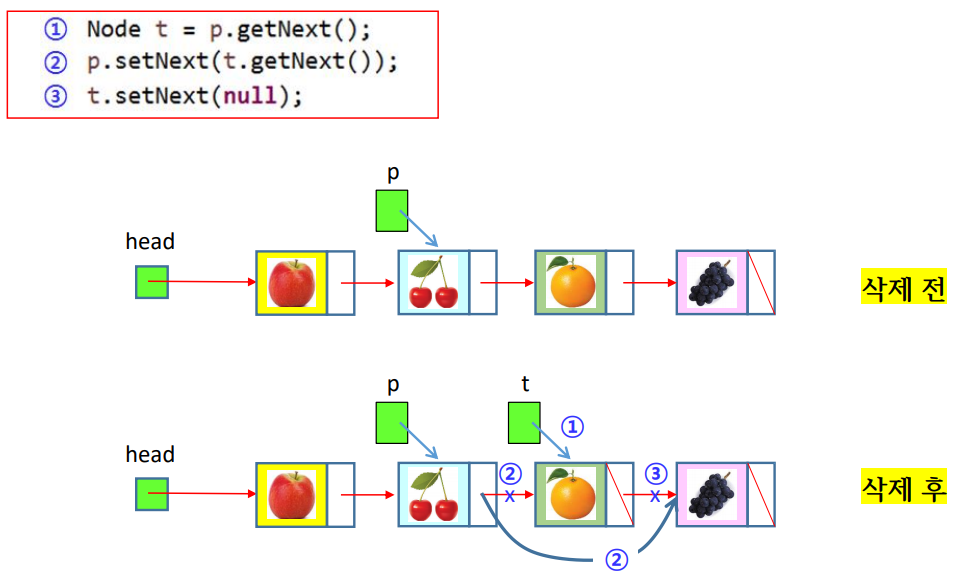
public void deleteAfter(Node p) { // p가 가리키는 노드의 다음 노드를 삭제
if (p == null) throw new NoSuchElementException();
Node t = p.getNext();
p.setNext(t.getNext());
t. setNext(null);
size--;
}
- p가 가리키는 노드의 다음 노드 삭제
main class
public class main {
public static void main(String[] args) {
SList<String> s = new SList<String>(); // 연결 리스트 객체 s 생성
s.insertFront("orange"); s.insertFront("apple");
s.insertAfter("cherry", s.head.getNext());
s.insertFront("pear");
s.print();
System.out.println(": s의 길이 = "+.size()+"\n");
System.out.println("체리가 \t"+s.search("cherry")+"번째에 있다.");
System.out.println("키위가 \t"+s.search("kiwi")+"번째에 있다.\n");
s.deleteAfter(s.head);
s.print;
System.out.println(": s의 길이 = "+s.size());System.out.println();
s.deleteFront();
s.print();
System.out.println(": s의 길이 = "+s.size());System.out.println();
SList<Integer> t = new SList<Integer>(); // 연결 리스트 객체 t 생성
t.insertFront(500); t.insertFront(200);
t.insertAfter(400, t.head);
t.insertFront(100);
t.insertAfter(300, t.head.getNext());
t.print();
System.out.println(": t의 길이 = "+t.size());
}
}
프로그램 출력 결과

수행 시간
- search() : 첫 노드부터 순차적 방문 - O(n)
- 삽입 / 삭제 연산 : 각각 O(1)개의 레퍼런스 갱신 - O(1)
- 단, insertAfter()나 deleteAfter()의 경우 이전 노드 p의 레퍼런스가 주어지지만, p의 레퍼런스가 주어지지 않는 삽입 / 삭제는 head로부터 p를 찾아야 하므로 O(n)
단일 연결 리스트의 응용 분야
- 스택, 큐 자료구조
- 체인닝
- 그래프 인접 리스트
- 매우 큰 정수의 산술 연산
- 비트코인의 블록체인
이중 연결 리스트
- 이중 연결 리스트(Doubly Linked List)는 각 노드가 2개의 레퍼런스를 가지고 이전 노드와 다음 노드를 가리키는 연결 리스트

- 단순 연결 리스트는 삽입이나 삭제할 때 이전 노드를 가리키는 레퍼런스를 알아야 하고, 역방향으로는 탐색할 수 없음
- 이중 연결 리스트는 단순 연결 리스트의 이러한 단점을 보완하나, 노드마다 메모리 사용
** 레퍼런스
다른 객체(노드)의 주소를 저장하고 있는 변수. 다른 노드를 가리키고 있는 변수(링크)
=> 어떤 노드 A가 노드 B를 저장하고 싶을 때 노드 A 안에 B의 위치(주소)를 저장하는 걸 레퍼런스(참조)라고 한다.
DNode class
public class DNode <E> {
private E item;
private DNode previous;
private Dnode next;
public DNode(E newItem, DNode p, DNode q) { // 노드 생성자
item = newItem;
previous = p;
next = q;
}
// getter & setter
public E getItem() { return item; }
public DNode getPrevious() { return previous; }
public DNode getNext() { retrurn next; }
public void setItem(E newItem) { item = newItem; }
public void setPrevious(DNode p) { previous = p; }
public void setNext(DNode q) { next = q; }
}
DList class
import java.util.NoSuchElementException;
public class DList <E> {
protected DNode head, tail;
protected int size;
public DList(){ // 생성자
head = new DNode (null, null, null);
tail = new DNode (null, head, null); // tail의 이전 노드를 head로 만든다.
head.setNext(tail); // head의 다음노드를 tail로 만든다.
size = 0;
}
// 삽입, 삭제 연산을 위한 method 선언
}
head와 tail이 가리키는 노드는 생성자에서 아래와 같이 초기화. 이 두 노드는 실제로 항목을 저장하지 않는 Dummy Node

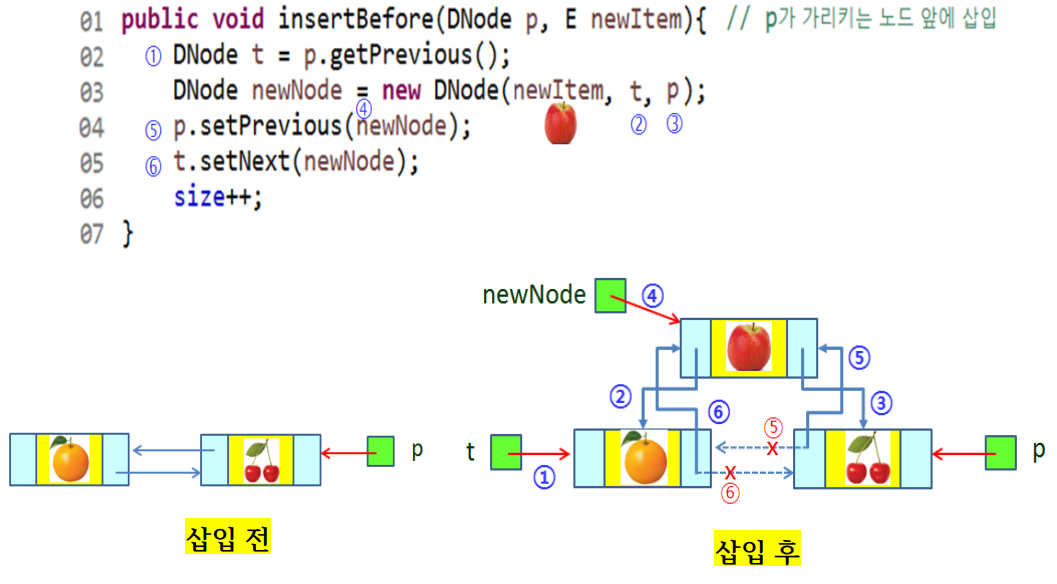
insertBefore(p)
public void insertBefore(DNode p, E newItem){
DNode t = p.getPrevious();
DNode newNode = new DNode(newItem, t, p);
p.setPrevious(newNode);
t.setNext(newNode);
size++;
}
노드 p 앞에 삽입
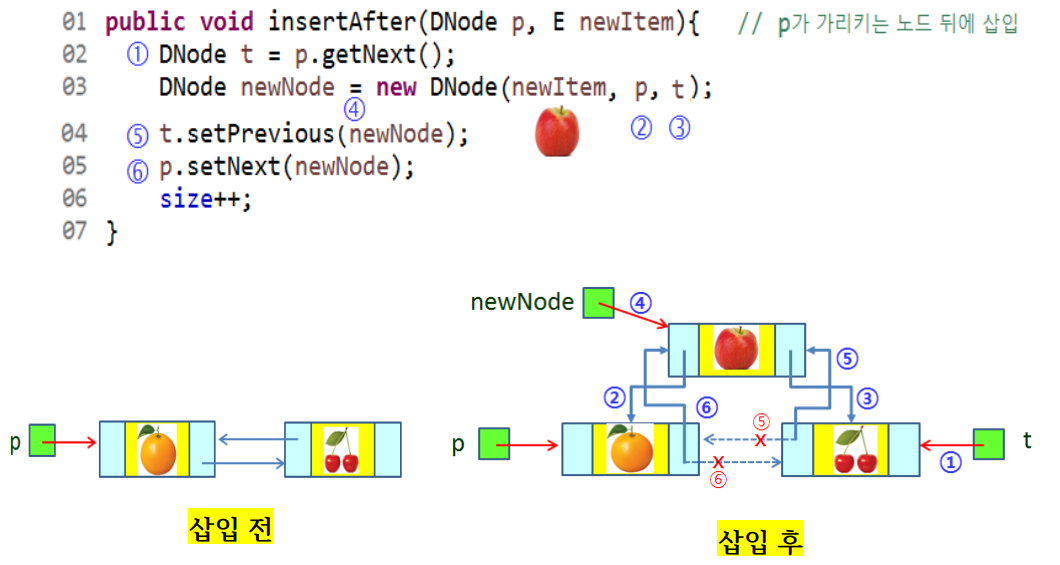
insertAfter(p)
- 노드 p 다음에 삽입
delete(x)
- 노드 x 삭제

main class
public class main {
public static void main(String[] args) {
DList<String> s = new DList<Stirng>(); // 이중 연결 리스트 객체 s 생성
s.insertAfter(s.head, "apple");
s.insertBefore(s.tail, "orange");
s.insertBefore(s.tail, "cherry");
s.insertAfter(s.head.getNext(), "pear");
s.print(); System.out.println();
s.delete(s.tail.getPrevious());
s.print(); System.out.println();
s.insertBefore(s.tail, "grape");
s.print(); System.out.println();
s.delete(s.head.getNext()); s.print(); s.delete(s.head.getNext()); s.print();
s.delete(s.head.getNext()); s.print(); s.delete(s.head.getNext()); s.print();
}
}
출력 결과 예시
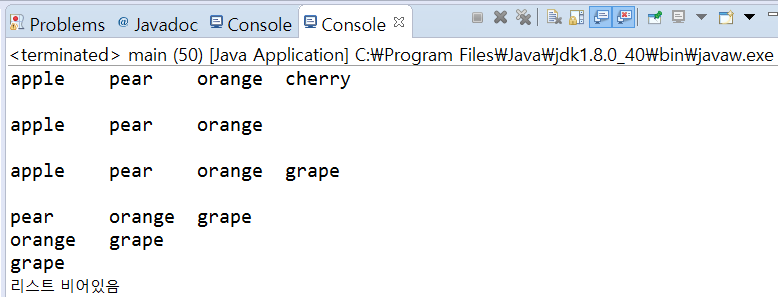
수행 시간
- 삽입 / 삭제 연산 : 각각 O(1) 개의 레퍼런스만 갱신 : O(1)
- 탐색 : head 또는 tail로부터 순차적으로 탐색 - O(n)
XOR 이중 연결 리스트
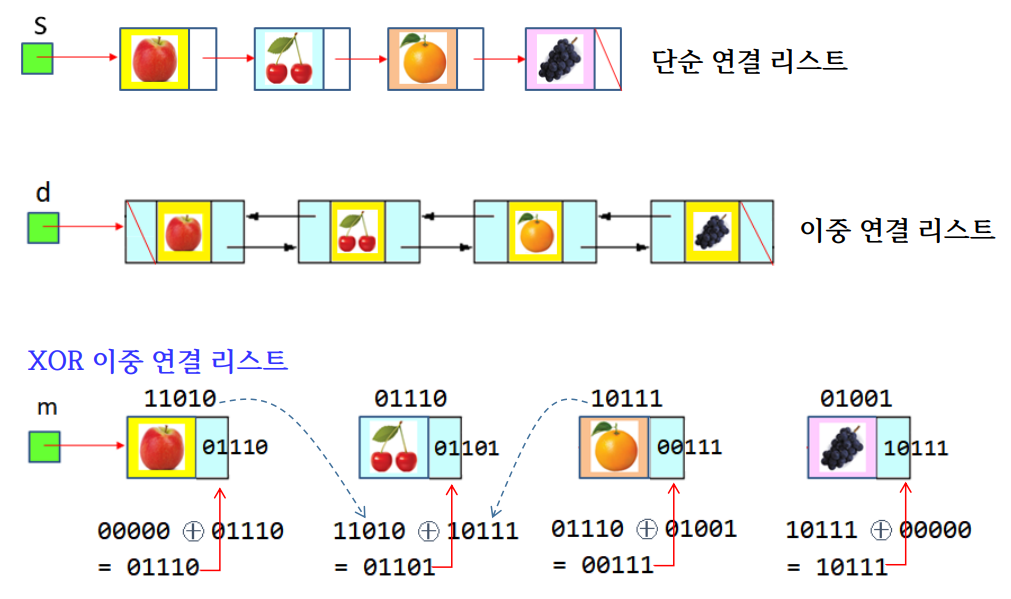

XOR 이중 연결 리스트 탐색







이중 연결 리스트의 응용
- 텍스트 편집기 undo / redo
- 웹페이지 이동
- 데크 자료구조
- 사진 슬라이드쇼
- 뮤직 플레이어
- 운영체제의 스레드 스케줄러
- 이항 힙(Binomial Heap)이나 피보나치 힙(Fibonacci Heap)과 같은 우선순위 큐를 구현하는 데에도 이중 연결 리스트가 부분적으로 사용
원형 연결 리스트
- 원형 연결 리스트(Circular Linked List)는 마지막 노드가 첫 노드와 연결된 단순 연결 리스트
- 원형 연결 리스트에서는 마지막 노드의 레퍼런스가 저장된 last는 단순 연결 리스트의 head와 같은 역할
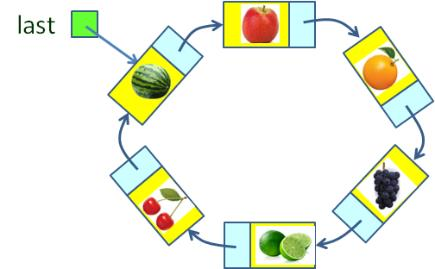
- 마지막 노드와 첫 노드를 O(1) 시간에 접근
- 리스트가 empty가 아니면 프로그램에서 null 조건을 검사하지 않아도 되는 장점
- 원형 연결 리스트에서는 반대 방향으로 노드들을 방문하기 쉽지 않으며, 무한 루프가 발생할 수 있음에 유의할 필요가 있다.
CList class
import java.util.NoSuchElementException;
public class CList <E> {
private Node last; // 리스트의 마지막 노드(항목을) 가리킨다.
private int size; // 리스트의 항목(노드) 수
public CList() { // 리스트 생성자
last = null;
size = 0;
}
// 삽입, 삭제 연산을 위한 메소드 선언
}
insert()
- 첫 노드로 삽입


delete()
- 첫 노드 삭제


main class
public class main {
public static void main(String[] args) {
CList<String> s = new CList<String>();
s.insert("pear"); s.insert("cherry");
s.insert("orange"); s.insert("apple");
s.print();
System.out.print(": s의 길이 = "+s.size()+"\n");
s.delete();
s.print();
System.out.print(": s의 길이 = "+s.size());System.out.println();
}
}
출력 결과

수행시간
- 삽입 / 삭제 연산 : 각각 O(1)개의 레퍼런스를 갱신 - O(1) 시간
- 탐색 연산 : 노드를 순차적으로 탐색 - O(n) 시간
원형 연결리스트의 응용
- 운영체제 CPU 스케줄러
- 이항 힙, 피보나치 힙
- 큐 자료구조 - front, rear 대신 1개의 last로 구현
- 게임 - Josephus 문제
최악의 경우 수행 시간 정리 표

Summary
- 리스트 : 일련의 동일한 타입의 항목의 나열
- 배열 : 동일한 타입의 원소들이 연속적인 메모리 공간에 할당되어 각 항목이 하나의 원소에 저장되는 기본적인 자료구조
- 단순 연결 리스트 : 동적 메모리 할당을 이용해 리스트를 구현하는 가장 간단한 형태의 자료구조
- 배열로 구현된 리스트 : 삽입 / 삭제 시 뒤따르는 항목들이 1칸씩 뒤나 앞으로 이동해야 하는 경우 발생
- 단순 연결 리스트에서는 삽입이나 삭제 시 노드들을 이동시킬 필요 없음
- 항목을 접근하기 위해서 순차 탐색을 해야 하고, 삽입 / 삭제 시 이전 노드를 가리키는 레퍼런스를 알아야 한다.
- 이중 연결 리스트는 항목을 접근하기 위해서 순차 탐색을 해야 하고, 삽입 / 삭제 시 이전 노드를 가리키는 레퍼런스를 알아야 한다.
- 각 노드에 2개의 레퍼런스를 가지며 각각 이전 노드와 다음 노드를 가리키는 방식의 연결 리스트
- 원형 연결 리스트는 마지막 노드가 첫 노드와 연결된 단수 연결 리스트
- 마지막 노드와 첫 노드를 O(1) 시간에 접근. 프로그램에서 null 조건 검사 불필요.